Establishing a RAG system at the enterprise level is becoming a significant strategy for businesses to take advantage of the power of LLMs. Instead of only relying on static, pretrained knowledge, RAG systems combine real-time retrieval with more sophisticated capabilities for generating new data.
A RAG system will provide responses that are fluent but also factual, relevant to the context of your organization, and ultimately based upon your organization’s information. This is especially important in an enterprise environment, as information is always changing, highly sensitive, and often located in unstructured formats.
This is intended to be your guide for RAG in the enterprise. This guide will help you understand not only what RAG is but also how to build something applicable and scalable. This guide will provide the necessary building blocks for creating a strong and effective RAG system using LLMs and a vector database. I will explain the basic architecture, describe essential parts of the system, and provide practical steps and best practices for implementation to give you a blueprint for building intelligent and production-ready solutions.
What Is an Enterprise RAG System?
While traditional AI provides predictive analysis, agentic AI will help us transition from simply analyzing data to taking action based on our analyses. Furthermore, traditional AI functions primarily as an assistive tool that generates predictive statistics (forecasting future demand, identifying inefficiencies); whereas agentic AIs will perform complex data analysis in real-time and take physical actions autonomously based upon those analyses aligned with established objectives. A few additional characteristics of agentic AI include:
• Ability to have access to, and analyze, large quantities of diverse data nearly instantaneously
• Ability to make informed decisions based on set rules, which are based on historical data or have been mutually agreed upon
• Perform tasks automatically
• Continue learning and refining performance over time, meaning the system does not just make suggestions about how to solve problems; it actually solves them.
The supply chain AI agents that are currently in use are functioning as autonomous decision-making units and managing tasks such as ordering inventory, altering logistical routes, or balancing warehouse stock in real time.
Why Businesses Need RAG Systems Today
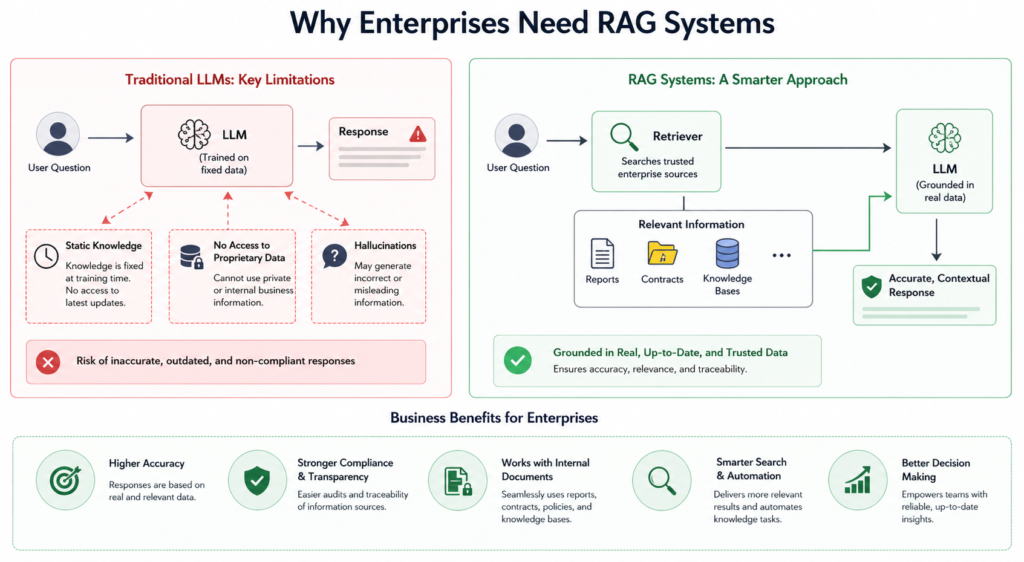
Enterprise use of traditional LLMs (large language models) has been limited due to their fixed knowledge base after training, inability to access new updates or proprietary company data, and resultant inaccuracies in responses (in some instances they have “hallucinated”—provided an answer that sounds plausible but did not correspond with any real-world data).
RAGs (retrieval-augmented generation LLMs) overcome these limitations using real, retrievable data to anchor every response generated by the model to real, trustworthy data (as well as from the internal knowledge base of the organization), providing accurate outputs that are based on the most current knowledge available to the organization.
In addition, they also allow for seamless interaction with a variety of types of documents (reports, contracts, knowledge bases) and lead to greater compliance, transparency and push for better decision-making because they allow for enterprises to utilize reliable automation, intelligent searching capabilities and ultimately better decision-making.
Core Architecture of a RAG System
An enterprise RAG system typically consists of three main stages: data ingestion, retrieval, and generation. Each stage plays a crucial role in ensuring the system delivers accurate and efficient results.
Data Ingestion Layer
The ingestion layer is responsible for collecting and preparing enterprise data. This includes documents, databases, APIs, and other structured or unstructured sources. The data is cleaned, normalized, and split into smaller chunks to make retrieval more effective.
Each chunk is then converted into a vector representation using an embedding model. These vectors capture the semantic meaning of the text and are stored in a vector database for fast retrieval.
Retrieval Layer
When a user submits a query, it is also converted into a vector. The system then searches the vector database to find the most similar chunks of data. This process is known as semantic search.
Advanced systems often use hybrid retrieval, combining vector search with keyword-based methods to improve accuracy. Some systems also include a reranking step to prioritize the most relevant results.
Generation Layer
In the final stage, the retrieved data is combined with the user’s query and passed to an LLM. The model uses this context to generate a response that is both relevant and grounded in real information.
This approach ensures that the output is not only fluent but also factually accurate and aligned with enterprise data, further reinforcing why explainable AI matters in production systems.
Understanding the Core Architecture of Enterprise RAG Systems
Building a robust RAG system requires several interconnected components, each serving a specific purpose.
Data Sources
Enterprise data can come from a wide range of sources, including internal documents, knowledge bases, CRM systems, APIs, and databases. The quality and structure of this data directly impact the performance of the RAG system.
Embedding Models
Embedding models convert text into numerical vectors that represent semantic meaning. These vectors enable similarity-based search, which is the foundation of RAG systems.
Vector Database
A vector database stores embeddings and allows for fast similarity searches. It uses algorithms like Approximate Nearest Neighbor (ANN) to efficiently retrieve relevant data, even at a large scale.
Retriever
The retriever is responsible for querying the vector database and fetching the most relevant chunks of data based on the user’s query.
Reranker
A reranker improves the quality of retrieved results by reordering them based on relevance. This step is especially important in enterprise systems where precision matters.
LLM (Generator)
The LLM generates the final response by combining the user query with the retrieved context. It ensures the output is coherent, natural, and informative.
Orchestration Layer
This layer manages the entire pipeline, coordinating data flow between components. It ensures that ingestion, retrieval, and generation work seamlessly together.
How to Build a RAG System: A Step-by-Step Guide
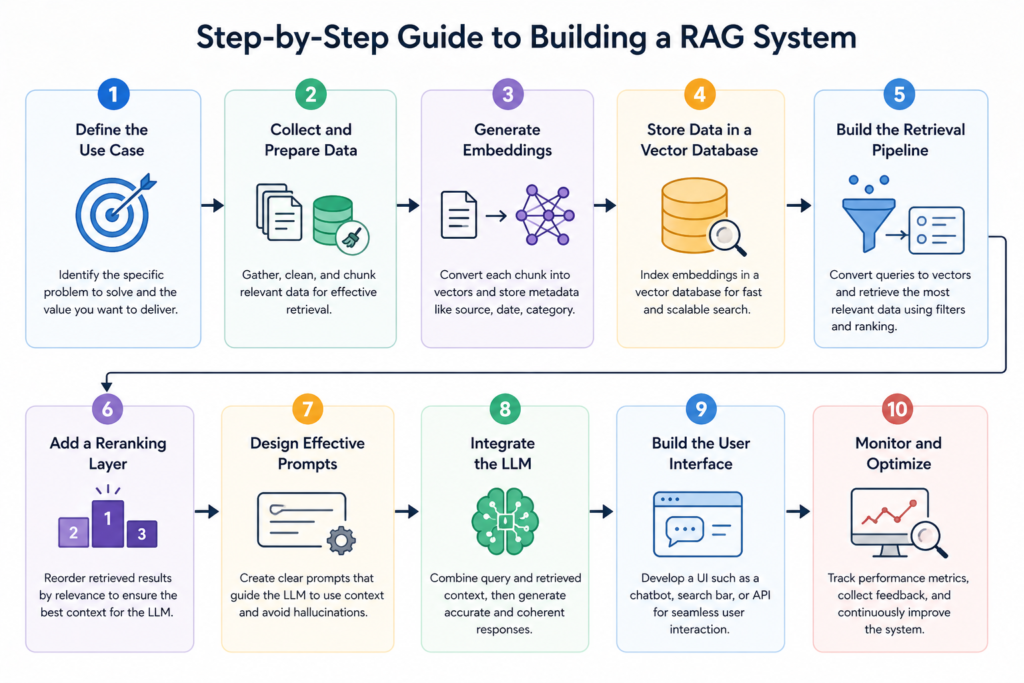
Step 1: Define the Use Case
Start by identifying the specific problem you want to solve. This could be a customer support chatbot, an internal knowledge assistant, or a document search system. A clear use case helps guide design decisions and ensures the system delivers measurable value.
Step 2: Collect and Prepare Data
Gather all relevant enterprise data and clean it to remove duplicates and inconsistencies. Then split the data into manageable chunks. Proper chunking is essential, as it directly affects retrieval accuracy.
Step 3: Generate Embeddings
Use an embedding model to convert each data chunk into a vector. Store these vectors along with metadata such as source, date, and category.
Step 4: Store Data in a Vector Database
Index the embeddings in a vector database to enable fast and scalable search. Choose a database that supports high performance and low latency.
Step 5: Build the Retrieval Pipeline
Convert user queries into embeddings and retrieve the most relevant data from the database. Apply filters and ranking techniques to refine the results.
Step 6: Add a Reranking Layer
Use a reranker to improve the quality of retrieved data. This ensures that the most relevant information is passed to the LLM.
Step 7: Design Effective Prompts
Prompt engineering plays a key role in RAG systems. The prompt should instruct the LLM to use the provided context and avoid generating unsupported information.
Step 8: Integrate the LLM
Combine the query and retrieved context, then pass them to the LLM to generate the final response.
Step 9: Build the User Interface
Develop an interface where users can interact with the system. This could be a chatbot, a search bar, or an API integrated into existing tools.
Step 10: Monitor and Optimize
Track system performance using metrics such as accuracy, latency, and user satisfaction. Continuously refine the system based on feedback and new data.
Advanced Techniques in Enterprise RAG
Hybrid Search
Hybrid search combines semantic and keyword-based retrieval, improving both recall and precision. This is particularly useful for enterprise data with diverse formats.
Query Transformation
Techniques like query expansion and decomposition help improve retrieval by generating multiple variations of a query.
Context Compression
To reduce token usage and improve efficiency, systems can compress retrieved data while preserving essential information.
Graph-Based RAG
GraphRAG uses knowledge graphs to represent relationships between entities, enabling more advanced reasoning and contextual understanding.
Agentic RAG
In this approach, the system can autonomously decide when to retrieve data and how to process it, enabling more complex workflows.
Challenges in Building Enterprise RAG Systems
Data Quality Issues
Poor-quality data leads to poor results. Ensuring clean, well-structured data is critical for success.
Latency
Combining retrieval and generation can introduce delays. Optimization techniques are needed to maintain a smooth user experience.
Security and Compliance
Enterprise data is often sensitive. Systems must include access controls, encryption, and audit mechanisms to ensure compliance.
Scalability
Handling large volumes of data requires distributed systems and efficient indexing strategies.s
Evaluation Complexity
Measuring the effectiveness of a RAG system is challenging, as it involves both retrieval accuracy and generation quality.
How to Build an Enterprise RAG System Using LLMs and Vector Databases
Focus on Data First
High-quality, well-organized data is the foundation of a successful RAG system, as it directly impacts the accuracy of retrieved information. Clean, structured, and up-to-date data ensures better indexing and more relevant results. Investing in proper data preparation ultimately leads to more reliable and efficient system performance.
Use Hybrid Retrieval
By using more than one retrieval method to enhance the system’s capability of retrieving accurate and pertinent data, combining multiple retrieval techniques will provide improved precision and recall when comparing retrieval methods, thus providing both better overall reliability in retrieving relevant results and better overall performance in retrieving results from the real world.
Optimize Chunking Strategy
The correct size of chunks is very important for the retrieval of information and understanding context. If your chunks are too small, you will lose context. On the other hand, if your chunks are too big, you will have irrelevant information. Therefore, you need to find the right balance between two extremes so that you get accurate information and responses.
Implement Guardrails
Establish clear guardrails to minimize hallucinations and keep outputs grounded in verified data. Define rules that guide the model to rely only on retrieved context and avoid unsupported claims. This also ensures responses stay aligned with business policies and compliance requirements.
Continuously Monitor Performance
Use feedback loops and analytics to continuously refine and improve the system over time. By analyzing user interactions, response accuracy, and performance metrics, you can identify gaps and optimize both retrieval and generation. This ongoing improvement ensures the RAG system becomes more accurate, efficient, and aligned with user needs.
Why RAG Systems Are Essential for Modern Enterprises
Enterprise retrieval augmented generation (RAG) systems have moved far beyond the realm of being just an idea and are now changing the way that businesses within different sectors gather and utilize data.
These RAG systems operate by combining synchronous access to real-time information with machine learning developed through intelligent generation methods.
As a result, these types of RAG systems are allowing organizations to work more quickly, minimize the time required for manual labor, and make better-informed decisions.
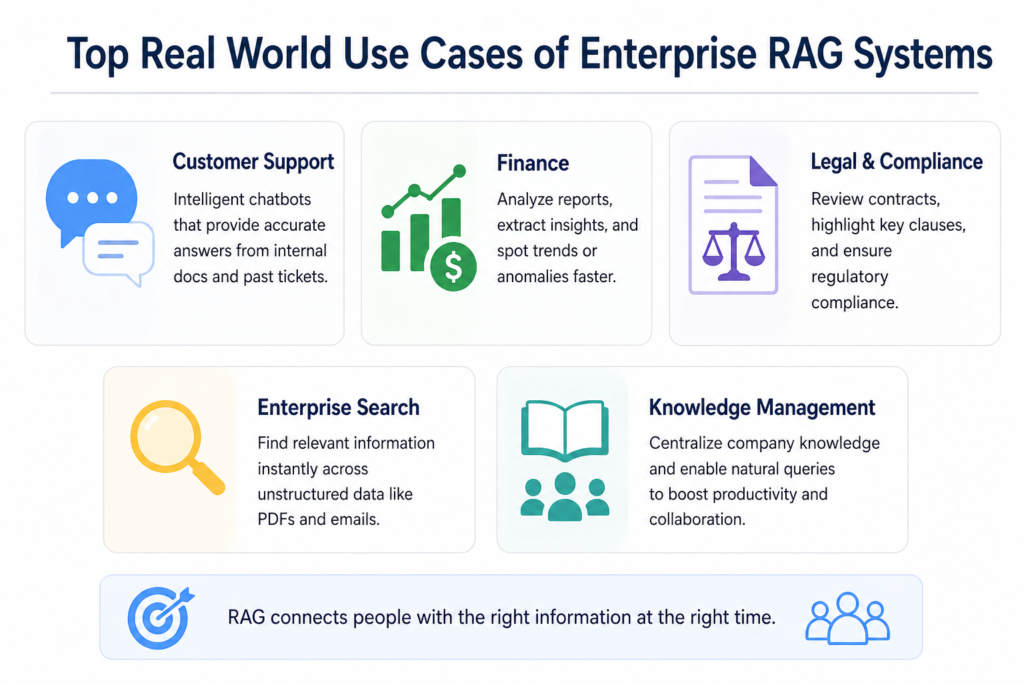
Below are several examples of how RAG systems are currently used across various industries:
- Customer Service: Providing customers with automated chat support that goes beyond static, frequently asked questions (FAQs), by leveraging internal resources (e.g. all internal documentation, past ticket history, and all help center pages) in real-time to provide consumers with accurate answers and quick response times.
- Finance: Helping financial staff analyze vast quantities of financial reports, identify pertinent data points (e.g., trend analysis), recognize any inconsistencies (e.g., anomalies), enhance the quality of business decisions, and minimize the amount of time it takes to gather answers.
- Legal/Regulatory Compliance: Providing legal teams with assistance during the review process by highlighting significant contract provisions/compliance issues while decreasing the number of hours spent by the team reviewing the contract with respect to compliance issues, thus increasing the accuracy of the review process.
- Enterprise Search: Replacing traditional keyword-based searching with semantic-based searching. This allows employees to find the information that they need quickly (on average, within seconds), regardless of whether it originates from a structured source, such as relevant documents/reports or unstructured sources (e.g., PDF files and emails).
- Knowledge Management: Aggregating disparate company data into one central, intelligent knowledge management system that enables employees to query such data in a more natural manner, resulting in increased employee productivity and increased employee collaboration.
Across all these use cases, the real value of RAG lies in its ability to connect people with the right information at the right time, making enterprise systems smarter, faster, and far more useful.
The Future of Enterprise RAG Systems and AI Innovation
With technology continuing to develop rapidly, the RAG model continues to grow rapidly as well. Improvements in agent-based AIs, real-time data integration, and multi-modal capabilities have all fueled the development of modern RAG architecture, leading to less reliance on basic document retrieval methods and increased autonomy through AI agents capable of making judgements about when it is appropriate to retrieve information, how they refine queries, and how to complete complex tasks by performing multi-step procedures. Additionally, real-time data pipelines support RAG systems pulling continuously updated data from APIs, databases, and streaming data sources to provide real-time responses that are always relevant and accurate.
Another major change occurring with RAG technology is the rapid growth of multi-modal RAG systems that are able to process, retrieve, and present all types of content, including images, audio, and structured data. This provides ample new opportunities for companies to develop new use cases such as image document analysis, voice-activated assistants, and richer knowledge discovery experiences. As RAG technology matures and continues to develop for organizations implementing AI, RAG is expected to be a common architecture and support the next generation of data-driven applications with additional intelligent functions, adaptive functions, and context-aware functions, which will provide smarter, more dependable, trustworthy, and aligned with the actual world.
Conclusion
Creating an enterprise RAG system involves far more than just the integration of an LLM and a database; it is a fully functioning, intelligent pipeline where data ingestion, retrieval, and generation all work together effectively. Each layer from the processing of the data to how the resultant data is processed is vitally important to ensuring a smooth and reliable user experience.
By providing organizations with seamless access to their data using both vector databases and LLM technology, organizations can greatly enhance the way they access, retrieve, use, and interact with information. Rather than looking for information in disparate documents or relying on stale knowledge, teams can now access immediate, accurate, and relevant information that is contextualized for their needs. As a result, not only does this improve operational efficiencies, but it also supports faster and more informed decision-making processes throughout the organization.
If a RAG system is built with strong architecture with best practices, it can become a strategic asset for an organization – enabling the organization to realize the full potential of their data, drive innovation, and maintain a competitive advantage in an AI driven world.


